
Facebook Researchers Develop a Neural Network That Predicts Body Movement Using Musical Input
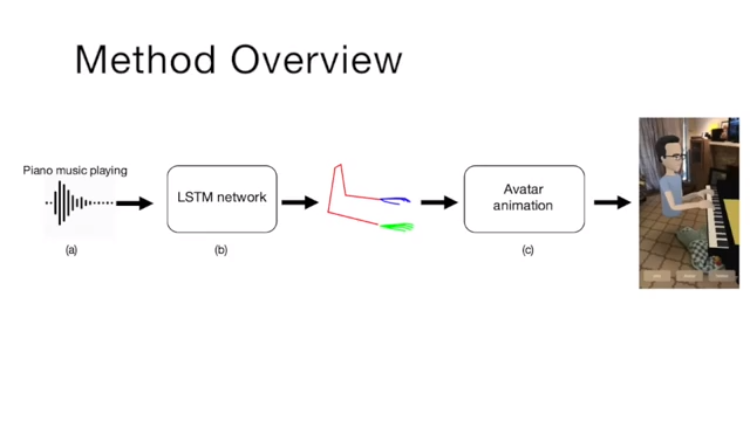
Facebook Researchers Eli Shlizerman, Lucio Dery, Hayden Schoen and Ira Kemelmacher Shlizerman, in partnership with the University of Washington and Stanford, have developed a groundbreaking LTSM network that predicts how a musicians body would move upon receiving audio input of an instrument being played. The prediction results in an animated skeleton, which they hope can be further refined into more accurate avatar. Their findings were presented at the 2018 Computer Vision and Pattern Recognition conference.
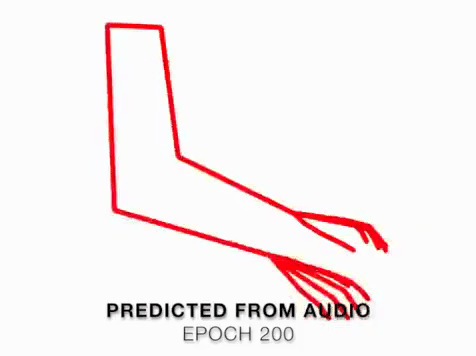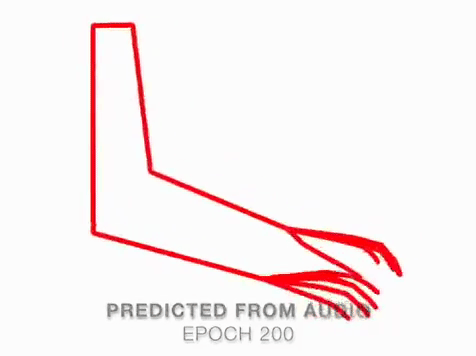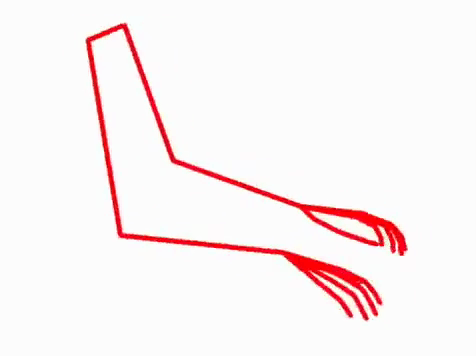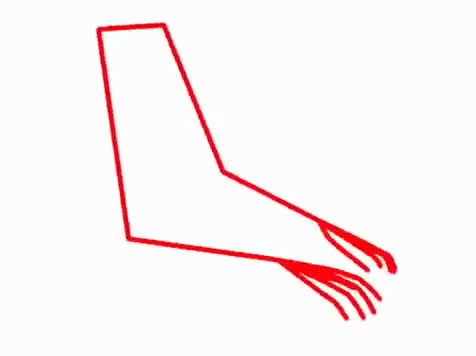
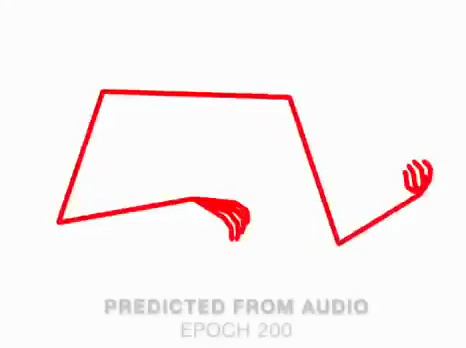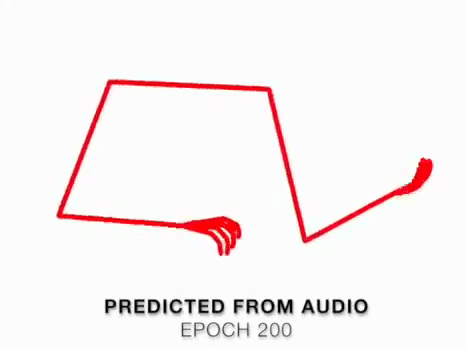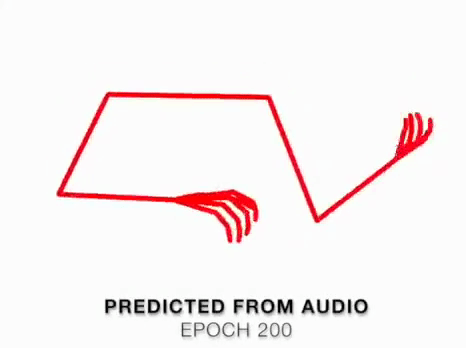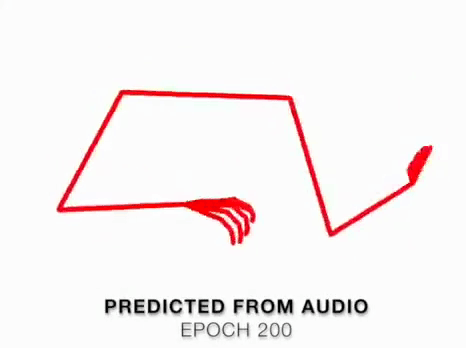
We present a method that gets as input an audio of violin or piano playing, and outputs a video of skeleton predictions which are further used to animate an avatar. The key idea is to create an animation of an avatar that moves their hands similarly to how a pianist or violinist would do, just from audio. Aiming for a fully detailed correct arms and fingers motion is the ultimate goal, however, it’s not clear if body movement can be predicted from music at all. In this paper, we present the first result that shows that natural body dynamics can be predicted. We built an LSTM network that is trained on violin and piano recital videos uploaded to the Internet.
![]()
![]()
via Engadget






